<meta name="viewport" content="width=device-width, initial-scale=1">
<link rel="stylesheet" href="github-markdown.css">
<article class="markdown-body">
# TP files de priorité
Il y a 4 parties dans ce TP : nous allons implémenter des [files de priorité](https://algs4.cs.princeton.edu/24pq/) que nous utiliserons dans l'implémentation de l'algorithme
de plus court chemin de [Dijkstra](https://fr.wikipedia.org/wiki/Algorithme_de_Dijkstra).
Nous utiliserons cet algorithme pour implémenter un solveur du jeu [Le Compte est Bon](http://a.vouillon.online.fr/comptbon.htm) et ensuite une application
de [Seam Carving](https://www.aryan.app/seam-carving/).
## Préparation
Le projet est réalisé avec [Maven](https://en.wikipedia.org/wiki/Apache_Maven), qui va nous permettre de gérer facilement toutes les dépendances du projet,
le lancement des tests et l'exécution.
## I. Files de priorité
Vous allez réaliser dans cette partie une file de priorité `HeapPQ` en utilisant les tas, qui nous servira plus tard pour implémenter
l'algorithme de Dijkstra. L'interface des files de priorité suivante se trouve dans
le package `fr.insa_rennes.sdd.priority_queue`.
```java
public interface PriorityQueue<T> {
boolean isEmpty();
int size();
void add(T e);
T peek();
T poll();
}
```
* `boolean isEmpty()` rend `true` si la file de priorité est vide et `false` sinon.
* `int size()` retourne la taille de la file de priorité.
* `void add(T e)` ajoute l'élément `e` dans la file de priorité.
* `T peek()` rend l'élément en tête de la file de priorité.
* `T poll()` rend l'élément en tête de la file de priorité et le retire de la file.
On vous fournit une implémentation peu efficace de cette interface dans la classe `OrderedArrayPQ<T>` du package `fr.insa_rennes.sdd.priority_queue`.
Cette classe va vous permettre d'avoir un exemple pour deux points particuliers de l'implémentation.
```java
public class OrderedArrayPQ<T> implements PriorityQueue<T> {
private static final int DEFAULT_INITIAL_CAPACITY = 8;
(3) private Comparator<? super T> comparator;
private int size;
private T[] array;
public OrderedArrayPQ() {
this(DEFAULT_INITIAL_CAPACITY, null);
}
@SuppressWarnings("unchecked")
(11) public OrderedArrayPQ(int initialCapacity, Comparator<? super T> comparator) {
if (initialCapacity < 1) {
throw new IllegalArgumentException();
}
array = (T[])new Object[initialCapacity];
this.comparator =
(17) comparator == null ? (t1, t2) -> ((Comparable<? super T>)t1).compareTo(t2) : comparator;
}
@Override
public void add(T e) {
if (e == null) {
throw new NullPointerException();
}
if (size >= array.length) {
(25) grow();
}
int index = Arrays.binarySearch(array, 0, size, e, comparator);
if (index >= 0) {
insert(e, index);
} else {
insert(e, -(index + 1));
}
size++;
}
}
```
1) À la ligne 3 on peut voir le comparateur Java qui va permettre d'ordonner les éléments de la file. L'utilisateur peut le fournir
au constructeur à la ligne 11, mais s'il ne le fournit pas, on utilise [l'ordre naturel](https://docs.oracle.com/javase/tutorial/collections/interfaces/order.html) du type `T` à la ligne 17^[C'est réalisé ainsi dans la classe `PriorityQueue` de Java.] (qui existe pour les `Comparable`).
Si l'utilisateur ne fournit pas de comparateur et que le type `T` ne permet pas d'être comparé, il en résultera une erreur à l'exécution.
Vous pourrez réutiliser cette façon de procéder dans votre implémentation.
2) À la ligne 25, on peut voir l'appel à la méthode `grow` qui permet de redimensionner le tableau `array` si celui-ci devient trop petit. Vous pourrez utiliser `grow` de la même manière
dans votre implémentation.
Vous devez compléter la classe `HeapPQ` pour implémenter maintenant une version efficace de la file de priorité en utilisant [un tas](https://fr.wikipedia.org/wiki/Tas_(informatique)).
Vous pouvez tester votre classe avec les tests `JUnit` dans l'ordre suivant.
* `HeapPQTest`.
* `HeapPQQuickCheckTest`.
* `AllPQQuickCheckTest`.
Vous pouvez lancer les tests depuis `Eclipse` ou bien en ligne de commande avec `Maven`. Pour lancer tous les tests du projet on utilise la commande suivante.
```bash
mvn test
```
Pour lancer un test spécifique, par exemple le test `HeapPQTest`, on utilise la commande suivante.
```bash
mvn -Dtest=HeapPQTest test
```
Votre implémentation devrait normalement avoir une complexité en $O(\log n)$ avec $n$ la taille de la file pour les méthodes `add` et `poll` contre une complexité en $O(n)$ pour la
classe `OrderedArrayPQ<T>`, autant dire que la différence en temps devrait être très visible. Vous pouvez exécuter la classe `PoorBenchmarkPQ` qui va
comparer les deux implémentations. Normalement il faudrait
utiliser une bibliothèque comme [JMH](https://openjdk.java.net/projects/code-tools/jmh/), par exemple, pour faire du benchmarking plus précis, mais vu la différence
énorme de temps d'exécution, notre simple classe suffira.
## II. Dijkstra
L'algorithme de [Dijkstra](https://fr.wikipedia.org/wiki/Algorithme_de_Dijkstra) va nous permettre de rechercher le plus court chemin d'un sommet d'un graphe vers tous les autres. Pour l'utiliser, nous avons tout
d'abord besoin de représenter un graphe. L'interface `Graph<T>` du package `fr.insa_rennes.sdd.graph` va nous permettre de décrire un graphe dont les sommets sont de type `T`.
```java
public interface Graph<T> {
int numberOfVertices();
int numberOfEdges();
void addVertex(T v);
void addEdge(T u, T v, double weight);
Iterable<VertexAndWeight<T>> neighbors(T u);
}
```
* `int numberOfVertices()` rend le nombre de sommets.
* `int numberOfEdges()` rend le nombre d'arcs.
* `void addVertex(T v)` permet d'ajouter le sommet `v`.
* `void addEdge(T u, T v, double weight)` ajoute l'arc entre les sommets `u` et `v` avec le poids `weight`.
* `Iterable<VertexAndWeight<T>> neighbors(T u)` rend un itérable sur les couples `(sommet, poids)` représentant les voisins du sommet `u` avec le poids des arcs entre `u` et le
voisin donné.
La classe `VertexAndWeight` permet de représenter un couple `(sommet, poids)`.
```java
public class VertexAndWeight<T> {
public final T vertex;
public final double weight;
public VertexAndWeight(T vertex, double weight) {
this.vertex = vertex;
this.weight = weight;
}
}
```
Un exemple d'implémentation d'un graphe simple où les sommets sont des entiers vous est donné dans la classe `IndexedGraph`. Par exemple,
on pourrait représenter le graphe suivant,
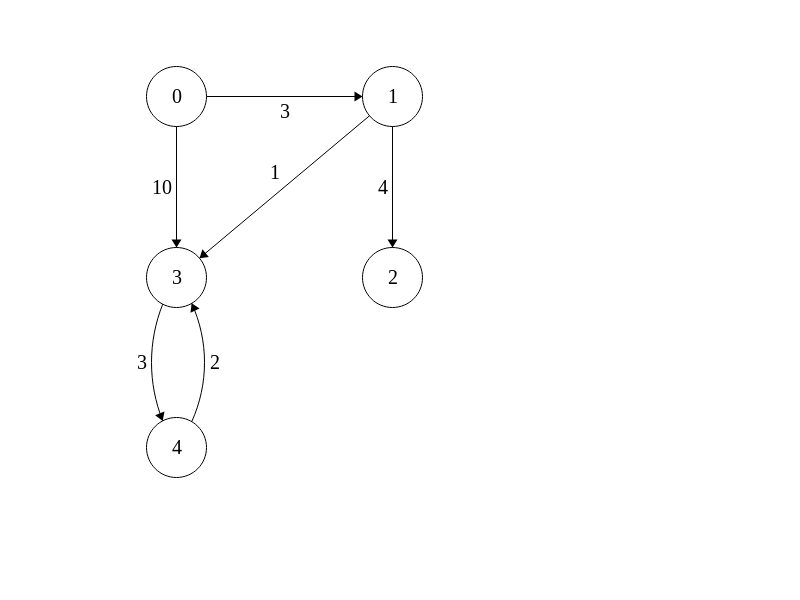
en faisant,
```java
public static void main(String[] args) {
Graph<Integer> g = new IndexedGraph(5);
g.addEdge(0, 1, 3);
g.addEdge(0, 3, 10);
g.addEdge(1, 2, 4);
g.addEdge(1, 3, 1);
g.addEdge(3, 4, 3);
g.addEdge(4, 3, 2);
}
```
Vous allez maintenant implémenter l'algorithme de [Dijkstra](https://fr.wikipedia.org/wiki/Algorithme_de_Dijkstra). La classe `Dijkstra<T>` du package `fr.insa_rennes.sdd.dijkstra`
est une ébauche à compléter.
```java
public class Dijkstra<T> {
private final PriorityQueue<DijkstraNode<T>> pq;
private final Map<T, Double> cost = new HashMap<>();
private final Map<T, T> prev = new HashMap<>();
public Dijkstra(Graph<T> graph, T source) {
this(graph, source, FactoryPQ.newInstance("HeapPQ"));
}
public Dijkstra(Graph<T> graph, T source, PriorityQueue<DijkstraNode<T>> pq) {
this.pq = pq;
solve(graph, source);
}
private void solve(Graph<T> graph, T source) {
// TO DO
}
public Deque<T> getPathTo(T v) {
// TO DO
}
public double getCost(T v) {
return cost.getOrDefault(v, Double.POSITIVE_INFINITY);
}
public boolean hasPathTo(T v) {
return getCost(v) != Double.POSITIVE_INFINITY;
}
}
```
* `void solve(Graph<T> graph, T source)` lance toute la recherche à partir du sommet `source` du graphe `graph`. Cette méthode utilisera
l'attribut `pq` comme file de priorité. Elle remplira les attributs `cost` et `prev` durant cette recherche.
* `cost` est une table d'association entre un sommet et un réel, permettant de connaître le coût minimum pour aller de la source vers un certain sommet.
* `prev` permet de donner le sommet prédécesseur d'un sommet donné vers la source. Cette table d'association permettra de coder la méthode `getPathTo`.
* `Deque<T> getPathTo(T v)` rend une collection qui donne le chemin pour aller de la source vers le sommet `v`. Grâce à la table `prev`, on peut connaître le prédécesseur de `v`, puis
le prédécesseur du prédécesseur et ainsi de suite, jusqu'à retomber sur le sommet source.
La classe `DijkstraNode<T>` permet de représenter un sommet (avec sa distance depuis la source et son prédécesseur) pendant la recherche dans `solve`. La file de priorité `pq` contient
des `DijkstraNode`.
```java
public class DijkstraNode<T> implements Comparable<DijkstraNode<T>> {
final Double cost;
final T vertex;
final T prev;
public DijkstraNode(Double cost, T vertex) {
this(cost, vertex, null);
}
public DijkstraNode(Double cost, T vertex, T prev) {
this.cost = cost;
this.vertex = vertex;
this.prev = prev;
}
@Override
public int compareTo(DijkstraNode<T> node) {
return Double.compare(cost, node.cost);
}
}
```
`int compareTo(DijkstraNode<T> node)` permet de comparer deux noeuds suivant leur distance à la source. Ainsi, l'élément à la racine du tas de la file de priorité `pq` sera celui
ayant la distance la plus petite à la source.
L'implémentation de l'algorithme de Dijkstra avec une file de priorité peut se décrire assez succinctement.
1. Initialement, on met dans la file de priorité `pq` la source avec une distance de 0.
2. Tant que `pq` n'est pas vide,
3. On retire le premier `DijkstraNode n` de la file.
4. On regarde si le sommet `n.vertex` que l'on vient de sortir de la file à déjà été traité (en regardant s'il est présent dans `cost`). Si oui, on va en `2`, sinon on continue.
5. On met à jour les tables `cost` et `prev` grâce à `n`.
6. Pour chaque voisin `v` de `n.vertex`,
7. On calcule la distance à `v` en fonction de `n` et on ajoute un nouveau `DijkstraNode` à le file de priorité `pq`.
Une petite animation de l'algorithme de Dijkstra se trouve [ici](https://www.cs.usfca.edu/~galles/visualization/Dijkstra.html). On peut se demander l'utilité de l'étape 4. En fait,
l'implémentation qu'on vient de décrire s'appelle `LazyDijkstra`, des explications sont fournies [ici](https://www.cs.princeton.edu/courses/archive/spr10/cos226/lectures/15-44ShortestPaths-2x2.pdf)
au transparent 21, ou vous pouvez demander à votre encadrant 🙂.
Vous pouvez tester votre implémentation de Dijkstra en lançant le test `JUnit` `DijkstraTest`, sous eclipse ou en utilisant la commande suivante.
```bash
mvn -Dtest=DijkstraTest test
```
## III. Le compte est bon
Toute la promotion s'est prise de passion pour le jeu du [compte est bon](https://www.youtube.com/watch?v=t_4dAYk5ySY&t=). On voudrait devenir champion de la promotion et pour se faire,
on va se construire un solveur pour pouvoir s'entraîner.
On va utiliser l'algorithme de Dijkstra pour réaliser ce solveur. Le code du solveur est donné dans la classe `LeCompteEstBonSolver` du package `fr.insa_rennes.sdd.dijkstra`. Il vous
reste à créer le graphe qui va représenter l'espace de recherche du compte est bon.
La classe le `LeCompteEstBonGraph` se trouve dans le package `fr.insa_rennes.sdd.graph`.
```java
(1) public class LeCompteEstBonGraph implements Graph<LeCompteEstBonGraph.State> {
(2) private int[] plaques;
(3) private double[] operatorsCost = {1, 1, 2, 6};
(4) private static final int ADD = 6;
(5) private static final int MINUS = 7;
(6) private static final int TIMES = 8;
(7) private static final int DIV = 9;
(8) private Map<State, HashSet<VertexAndWeight<State>>> adjacency = new HashMap<>();
(9) private Map<Integer, ArrayList<State>> compteToState = new HashMap<>();
private int numberOfEdges;
public LeCompteEstBonGraph(int...plaques) {
this.plaques = plaques;
}
public void setOperatorCost(int op, double cost) {
operatorsCost[op - ADD] = cost;
}
(20) public double getOperatorCost(int op) {
return operatorsCost[op - ADD];
}
public Map<Integer, ArrayList<State>> compteToState() {
return compteToState;
}
@Override
public int numberOfVertices() {
return adjacency.size();
}
@Override
public int numberOfEdges() {
return numberOfEdges;
}
@Override
public void addVertex(State v) {
throw new UnsupportedOperationException();
}
@Override
public void addEdge(State u, State v, double weight) {
throw new UnsupportedOperationException();
}
@Override
public Iterable<VertexAndWeight<State>> neighbors(State s) {
if (adjacency.containsKey(s)) {
return adjacency.get(s);
}
HashSet<VertexAndWeight<State>> neighbors = s.neighbors();
adjacency.put(s, neighbors);
for (VertexAndWeight<State> vw : neighbors) {
int compte = vw.vertex.getCompte();
if (compte == State.UNFINISHED) continue;
if (!compteToState.containsKey(compte)) {
compteToState.put(compte, new ArrayList<>());
}
compteToState.get(compte).add(vw.vertex);
}
numberOfEdges += neighbors.size();
return neighbors;
}
public State initialState() {
return new State(0, State.UNFINISHED);
}
(71) public class State {
(72) private static final int UNFINISHED = -1;
(73) private static final int IMPOSSIBLE = -2;
(74) private long stack;
private int compte;
private State(long stack, int compte) {
this.stack = stack;
this.compte = compte;
}
public int getCompte() {
return compte;
}
(84) private HashSet<VertexAndWeight<State>> neighbors() {
HashSet<VertexAndWeight<State>> neighbors = new HashSet<>();
// TO DO
return neighbors;
}
private SmallSet plaques(long stack) {
SmallSet res = new SmallSet();
int n = size(stack);
for (int i = 1; i <= n; i++) {
int v = get(stack, i);
if (v < ADD) {
res.insert(v);
}
}
return res;
}
(100) private int compte(long stack) {
// TO DO
return UNFINISHED;
}
(104) private int get(long stack, int index) {
return (int) ((stack & (0xFL << index * 4)) >>> index * 4);
}
private long set(long stack, int index, long v) {
stack = stack & ~(0xFL << index * 4);
stack = stack | (v << index * 4);
return stack;
}
(112) private int size(long stack) {
return get(stack, 0);
}
(115) private long push(long stack, int v) {
int n = get(stack, 0);
stack = set(stack, n + 1, v);
stack = set(stack, 0, n + 1);
return stack;
}
}
}
```
* L'attribut `plaques` à la ligne 2, représente les plaques du jeu. Elles sont au nombre de 6. On pourrait avoir par exemple `plaques = new int[]{1, 2, 7, 9, 25, 100}` pour
représenter les plaques `1`, `2`, `7`, `9`, `25`, `100`.
* L'attribut `operatorsCost` à la ligne 3, représente le coût associé aux différents opérateurs `+`, `-`, `*` et `/` respectivement. Quand on
passera d'un état du jeu à un autre, on attribuera un coût de 1 pour une plaque, et le coût de `operatorCost` pour un opérateur. Pour obtenir le coût d'une opération,
on utilisera la méthode `getOperatorCost` définie à la ligne 20. Par exemple, pour obtenir le coût de l'addition, on fera `getOperatorCost(ADD)`.
Pouvoir avoir un coût différent par opération nous permettra de préférer, par exemple, des solutions où il n'y a pas de divisions.
* Les attributs `ADD`, `MINUS`, `TIMES` et `DIV` aux lignes 4, 5, 6 et 7, sont des constantes permettant de représenter les opérateurs.
* L'attribut `adjacency` à la ligne 8, est la représentation du graphe sous forme de [listes d'adjacence](https://fr.wikipedia.org/wiki/Liste_d%27adjacence).
* L'attribut `compteToState` à la ligne 9, permet de faire le lien entre le résultat d'un calcul et l'état associé (on va définir ce qu'est un état juste après).
* On peut voir à la ligne 1 que le `CompteEstBonGraph` est un `Graph<LeCompteEstBonGraph.State>`. Les sommets de ce graphe sont des états qui vont permettre de représenter
les différents calculs, intermédiaires ou complets, que l'on peut réaliser avec les différentes plaques et opérateurs.
* La classe `State` est une classe interne de la classe `LeCompteEstBon` et sa définition est donnée à partir de la ligne 71. C'est cette classe que vous allez devoir compléter.
Cette classe va représenter les calculs en utilisant la [notation polonaise inverse](http://www-stone.ch.cam.ac.uk/documentation/rrf/rpn.html) qui nous permet de nous passer des parenthèses.
La classe `State` va donc conserver le calcul que l'état représente dans une pile contenant des plaques et des opérateurs. Par exemple, `10 5 - 2 +` représente `(10 - 5) + 2`.
* L'attribut `UNFINISHED` à la ligne 72, permet de représenter un état de calcul qui ne permet pas encore d'obtenir un résultat, par exemple l'état `1 2 3 +` ne permet pas encore d'obtenir un résultat.
Il faudrait un autre opérateur pour avoir un calcul complet, comme `1 2 3 + *` par exemple.
* L'attribut `IMPOSSIBLE` à la ligne 73, permet de représenter un état de calcul qui est impossible. En effet, lorsque vous allez générer les états voisins d'un état donné grâce à la méthode
`neighbors` définie à la ligne 84, vous allez essayer d'ajouter une plaque ou un opérateur à l'état courant et vérifier si le calcul est possible ou non. Par exemple, si on ajoute à l'état
`1 2 +` un opérateur `+`, on obtient l'état voisin `1 2 + +` qui représente un calcul impossible à faire ou à compléter.
* L'attribut `stack` à la ligne 74, représente la pile du calcul que représente cet état. On a choisi de représenter la pile par un `long` pour des raisons d'efficacité, car la pile ne sera
pas très grande (6 plaques et 5 opérateurs au maximum). Même si cette représentation peut vous paraître compliquée, vous pouvez la manipuler sans avoir à la comprendre dans les détails
grâce aux méthodes `get`, `size` et `push` définies ci-dessous. Nous allons donner un exemple de pile pour expliquer ces différentes méthodes. Soit le tableau
`plaques = new int[]{1, 3, 7, 10, 25, 100}`, pour le calcul `10 25 3 + *` la pile
`stack` sera représentée comme suit.
```
+-------+
5 | TIMES |
+-------+
4 | ADD |
+-------+
3 | 1 |
+-------+
2 | 4 |
+-------+
1 | 3 |
+-------+
0 | 5 |
+-------+
```
L'indice 0 contient la taille de la pile, ici 5. Les autres indices représentent les différents éléments du calcul. Notons que nous ne plaçons pas directement les nombres `10`, `25` et `3`
dans `stack` mais leurs indices dans le tableau `plaques`. Cette façon de faire permet de compresser et d'être indépendant de la taille des nombres dans `plaques`^[Vous pouvez aussi comprendre
maintenant pourquoi la constante `ADD` est égale à 6.].
* La méthode `int get(long stack, int index)` à la ligne 104 retourne l'élément d'indice `i` dans `stack`. Pour notre exemple, `get(stack, 3) == 1`.
* La méthode `int size(long stack)` à la ligne 112 rend la taille de la pile en paramètre. Pour notre exemple, `size(stack) == 5`.
* La méthode `long push(long stack, int v)` à la ligne 115 prend une pile en paramètre et en crée une nouvelle en ajoutant `v` en haut de la pile. Vous verrez normalement
l'utilité de cette méthode dans `neighbors`. Pour notre exemple, pour `push(stack, 2)`, on obtiendrait la nouvelle pile
```
+-------+
6 | 2 |
+-------+
5 | TIMES |
+-------+
4 | ADD |
+-------+
3 | 1 |
+-------+
2 | 4 |
+-------+
1 | 3 |
+-------+
0 | 6 |
+-------+
```
Vous pouvez maintenant compléter la méthode `int compte(stack)` à la ligne 100. Cette méthode prend une pile de calcul en paramètre et rend le résultat que représente ce calcul. Si
la pile ne représente pas un calcul valide, cette méthode rend la valeur `IMPOSSIBLE`. Si le calcul n'est pas encore terminé, par exemple `1 2 + 3`, cette méthode retourne `UNFINISHED`.
Pour réaliser cette méthode vous pouvez utiliser, si vous voulez, la structure de donnée `ArrayDeque` de Java. Vous pouvez ensuite tester la méthode `compte` en exécutant
le test `testCompte` de la classe de tests `LeCompteEstBonGraphTest` sous `Eclipse` ou en utilisant la commande suivante.
```
mvn -Dtest=LeCompteEstBonGraphTest#testCompte test
```
Il ne reste plus qu'à compléter la méthode `HashSet<VertexAndWeight<State>> neighbors()` à la ligne 84 et notre compte est bon sera opérationnel. La méthode `neighbors` va générer tous
les états possibles successeurs de l'état courant. Par exemple, si `plaques = new int[]{1, 3, 7, 10, 25, 100}` et que l'état courant est le suivant,
```
stack:
+-------+
4 | ADD |
+-------+
3 | 1 |
+-------+
2 | 4 |
+-------+
1 | 3 |
+-------+
0 | 4 |
+-------+
compte: UNFINISHED
```
la méthode `neighbors` rendra les états suivants.
```
stack: stack: stack: stack: stack:
+-------+ +-------+ +-------+ +-------+ +-------+
5 | ADD | 5 | TIMES | 5 | 0 | 5 | 2 | 5 | 5 |
+-------+ +-------+ +-------+ +-------+ +-------+
4 | ADD | 4 | ADD | 4 | ADD | 4 | ADD | 4 | ADD |
+-------+ +-------+ +-------+ +-------+ +-------+
3 | 1 | 3 | 1 | 3 | 1 | 3 | 1 | 3 | 1 |
+-------+ +-------+ +-------+ +-------+ +-------+
2 | 4 | 2 | 4 | 2 | 4 | 2 | 4 | 2 | 4 |
+-------+ +-------+ +-------+ +-------+ +-------+
1 | 3 | 1 | 3 | 1 | 3 | 1 | 3 | 1 | 3 |
+-------+ +-------+ +-------+ +-------+ +-------+
0 | 5 | 0 | 5 | 0 | 5 | 0 | 5 | 0 | 5 |
+-------+ +-------+ +-------+ +-------+ +-------+
compte: 38 compte: 280 compte: UNFINISHED compte: UNFINISHED compte: UNFINISHED
```
Notons que dans le jeu du compte est bon, on ne peut utiliser qu'une seule fois une plaque donnée, le résultat d'un calcul doit être positif
et une division doit être entière. Vous pouvez maintenant tester la méthode `neighbors` en lançant le test `testNeighbors` de la classe de tests `LeCompteEstBonGraphTest`
en utilisant `Eclipse` ou la commande suivante.
```
mvn -Dtest=LeCompteEstBonGraphTest#testNeighbors test
```
Pour lancer l'application dans un terminal, taper les commandes suivantes.
```bash
mvn package
mvn exec:java -Dexec.mainClass="fr.insa_rennes.sdd.dijkstra.LeCompteEstBonSolver"
```
## IV. Recadrage intelligent
Le [recadrage intelligent](https://en.wikipedia.org/wiki/Seam_carving) (*seam carving* en anglais) est une technique de redimensionnement d'images qui utilise le contenu
de l'image pour supprimer des pixels qui semblent moins importants. Une démonstration se trouve [ici](https://www.aryan.app/seam-carving/) et l'article
des auteurs de cette technique [ici](http://www.faculty.idc.ac.il/arik/SCWeb/imret/imret.pdf).
### Principe
L'idée du recadrage intelligent est d'utiliser une recherche de plus court chemin suivant un critère particulier pour trouver les pixels à supprimer dans l'image.
Considérons l'image 4x3 suivante.
<img src="figures/seam1.svg" width="550"/>
On peut voir dans chaque pixel de l'image les trois composantes `RGB` (rouges, vertes et bleues). Le `0` représente l'intensité minimale pour la composante
considérée et une valeur de `1` représente l'intensité maximale.
À partir de cette image, on va calculer l'énergie d'un pixel qui va nous donner l'importance de ce pixel. Plus l'énergie est élevée et plus le pixel sera
important. Par exemple, on peut attribuer une valeur élevée à un pixel s'il y a beaucoup de différence d'intensité entre lui et ses voisins
sur chaque composante `RGB`. On pourrait obtenir, pour l'image précédente, la grille d'énergie suivante.
<img src="figures/seam2.svg" width="550"/>
On peut voir que le pixel `(3, 0)` possède une forte énergie car il était entouré de pixels avec des intensités éloignées.
Le code qui s'occupe de calculer cette grille d'énergie se trouve dans la classe `SeamCarver` du package `fr.insa_rennes.sdd.seam_carving`.
```java
public abstract class SeamCarver {
protected Picture picture;
protected BiFunction<Double, Double, Double> energyFunction;
protected SeamCarver(Picture picture) {
(6) this(picture, (v1, v2) -> (v1 - v2) * (v1 - v2));
}
protected SeamCarver(Picture picture, BiFunction<Double, Double, Double> energyFunction) {
this.picture = picture;
this.energyFunction = energyFunction;
}
(14) protected double[][] energyMap() {
double[][] redEnergy = energy(picture.redPlane());
double[][] greenEnergy = energy(picture.greenPlane());
double[][] blueEnergy = energy(picture.bluePlane());
double[][] res = blueEnergy;
for (int row = 0; row < res.length; row++) {
for (int col = 0; col < res[0].length; col++) {
res[row][col] += redEnergy[row][col] + greenEnergy[row][col];
}
}
return res;
}
protected double[][] energy(double[][] channel) {
int h = channel.length;
int w = channel[0].length;
double[][] res = new double[h][w];
for (int row = 0; row < h; row++) {
for (int col = 0; col < w; col++) {
double v = channel[row][col];
double delta = row == 0 ? 0 : energyFunction.apply(v, channel[row - 1][col]);
res[row][col] += delta;
delta = row == h - 1 ? 0 : energyFunction.apply(v, channel[row + 1][col]);
res[row][col] += delta;
delta = col == 0 ? 0 : energyFunction.apply(v, channel[row][col - 1]);
res[row][col] += delta;
delta = col == w - 1 ? 0 : energyFunction.apply(v, channel[row][col + 1]);
res[row][col] += delta;
}
}
return res;
}
}
```
La méthode `double[][] energyMap()` à la ligne 14 rend une matrice de `double` représentant l'énergie de chaque pixel de l'image `picture` en utilisant la fonction `energyFunction` dont la valeur par défaut est définie
à la ligne 6.
Maintenant que nous avons cette matrice avec l'énergie de chaque pixel, comment réduire l'image en prenant en compte cette information ?
Pour réduire verticalement, nous allons considérer la matrice d'énergie comme un graphe. Ce graphe est représenté ci-dessous.
<img src="figures/seam3.svg" width="800"/>
Vous pouvez remarquer que l'on a ajouté deux sommets : `Left` et `Right`. Les poids sur les arcs sont les valeurs d'énergie du pixel d'arrivé.
Par exemple, le poids de l'arc allant de `(0,0)` en `(1,1)` est l'énergie du pixel `(1,1)`^[Nous n'avons pas représenté tous les poids sur l'image pour ne pas allourdir la figure.].
Maintenant, nous allons utiliser `Dijkstra` sur ce graphe pour trouver le chemin de moindre énergie entre les sommets `Left` et `Right`. Nous obtenons alors le chemin suivant.
<img src="figures/seam5.svg" width="800"/>
Pour réduire l'image, il nous reste simplement à supprimer les pixels du chemin. Pour notre exemple, nous obtenons la figure suivante.
<img src="figures/seam6.svg" width="550"/>
Il reste enfin à compacter les colonnes pour supprimer les trous. Nous obtenons la figure suivante.
<img src="figures/seam7.svg" width="550"/>
Notons que pour continuer d'appliquer le recadrage intelligent à la nouvelle image, il faudra recalculer une matrice d'énergie à partir de cette nouvelle image.
Pour réduire horizontalement une image, on procède de façon similaire, mais à partir du graphe suivant.
<img src="figures/seam4.svg" width="550"/>
### Recadrage intelligent en utilisant Dijkstra
Pour construire les deux graphes que nous venons de présenter, vous devrez utiliser les deux classes `LeftToRightGridGraph` et `TopToBottomGridGraph` du package `fr.insa_rennes.sdd.graph`.
Pour créer le graphe allant de la gauche vers la droite à partir de la matrice d'énergie `energyMap`, il suffit d'exécuter la ligne suivante.
```java
new LeftToRightGridGraph(energyMap);
```
Le sommet `Left` est représenté par la classe `Coordinate.Left` et le sommet `Right` par la classe `Coordinate.Right`.
Pour créer un graphe allant du haut vers le bas, il suffit d'exécuter la ligne suivante.
```java
new TopToBottomGridGraph(energyMap);
```
Le sommet `Top` est représenté par la classe `Coordinate.Top` et le sommet `Bottom` par la classe `Coordinate.Bottom`.
Vous allez maintenant implémenter le recadrage intelligent en utilisant les graphes `LeftToRightGridGraph` et `TopToBottomGridGraph` et l'algorithme de `Dijkstra`. La classe que vous devez compléter
est la classe `SeamCarverDijkstra` du package `fr.insa_rennes.sdd.seam_carving`.
```java
public class SeamCarverDijkstra extends SeamCarver {
public SeamCarverDijkstra(Picture picture) {
super(picture);
}
public SeamCarverDijkstra(Picture picture, BiFunction<Double, Double, Double> energyFunction) {
super(picture, energyFunction);
}
@Override
public void reduceToSize(int width, int height) {
throw new UnsupportedOperationException();
}
@Override
public Deque<Coordinate> horizontalSeam() {
throw new UnsupportedOperationException();
}
@Override
public Deque<Coordinate> verticalSeam() {
throw new UnsupportedOperationException();
}
}
```
Vous devez compléter les méthodes suivantes.
* `Deque<Coordinate> horizontalSeam()` qui rend les coordonnées du plus court chemin entre les sommets `Left` et `Right`. Les coordonnées `Left` et `Right` n'y sont pas incluses.
* `Deque<Coordinate> verticalSeam()` qui rend les coordonnées du plus court chemin entre les sommets `Top` et `Bottom`. Les coordonnées `Top` et `Bottom` n'y sont pas incluses.
* `void reduceToSize(int width, int height)` qui reduit l'image `picture` aux dimensions `width x height`. Vous pouvez tout d'abord réduire l'image jusqu'à ce que sa largeur devienne `width` puis
ensuite la réduire jusqu'à ce que sa hauteur devienne `height`. Les méthodes `cropHorizontal` et `cropVertical` de la classe `SeamCarver` vous seront utiles.
* `void cropHorizontal(Deque<Coordinate> seam)` met à jour l'image `picture` en retirant toutes les coordonnées de `seam`. La hauteur de l'image va être réduite d'un pixel.
* `void cropVertical(Deque<Coordinate> seam)` met à jour l'image `picture` en retirant toutes les coordonnées de `seam`. La largeur de l'image va être réduite d'un pixel.
Vous pouvez tester en exécutant la commande suivante.
```bash
mvn javafx:run
```
Après avoir chargé l'image `src/main/ressources/demo.jpg`, vous pouvez visualiser les chemins en utilisant les options `Show Horizontal Seam` et `Show Verical Seam` du menu `Action`. Vous pouvez redimensionner
l'image en utilisant les flèches gauche et bas, la flèche gauche réduisant horizontalement et la flèche bas verticalement.
Le redimensionnement de la fenêtre avec la souris utilise aussi le recadrage intelligent.
### Recadrage intelligent en utilisant la programmation dynamique
Nous voudrions améliorer la vitesse d'exécution de notre recadrage intelligent. Dans notre implémentation actuelle, nous avons créé un graphe à partir de la matrice d'énergie
puis appliqué l'algorithme de `Dijkstra` sur celui-ci. Même si l'algorithme de `Dijkstra` est efficace, dans notre approche nous n'avons pas pris en compte les particularités de notre graphe. En prenant
en compte celles-ci nous pouvons faire encore mieux. Examinons le graphe qui va de la gauche vers la droite, reproduit ci-dessous, sans les sommets `Left` et `Right`.
<img src="figures/seam8.svg" width="600"/>
Étant donné que les arcs ne vont que de la gauche vers la droite, on peut calculer le plus court chemin depuis la gauche vers n'importe quelle case en une seule passe sur la matrice en partant de la gauche et en
progressant colonne par colonne vers la droite. La première colonne de la matrice contient juste les valeurs des sommets.
<img src="figures/seam9.svg" width="600"/>
Ensuite on passe à la colonne suivante. Pour connaître le plus petit coût depuis la gauche vers le sommet `(0, 1)` on va se servir des informations de la colonne précédente.
<img src="figures/seam10.svg" width="600"/>
On fait de même pour le sommet `(1,1)` et on obtient le résultat de la figure suivante.
<img src="figures/seam11.svg" width="600"/>
En continuant ainsi, on obtient la matrice complète suivante.
<img src="figures/seam12.svg" width="600"/>
On peut ensuite reconstruire à rebours le plus court chemin grâce à cette matrice.
<img src="figures/seam13.svg" width="600"/>
La complexité de notre implémentation de l'algorithme de `Dijkstra`, pour un graphe `g`, est en `O((g.numberOfVertices() + g.numberOfEdges()) * log(g.numberOfVertices()))`. La construction de la matrice
comme présentée précédemment est en `O(g.numberOfVertices() + g.numberOfEdges())`.
Vous devez compléter la classe `SeamCarverDP` du package `fr.insa_rennes.sdd.seam_carving`.
```java
public class SeamCarverDP extends SeamCarver {
public SeamCarverDP(Picture picture) {
super(picture);
}
public SeamCarverDP(Picture picture, BiFunction<Double, Double, Double> energyFunction) {
super(picture, energyFunction);
}
@Override
public void reduceToSize(int width, int height) {
throw new UnsupportedOperationException();
}
@Override
public Deque<Coordinate> horizontalSeam() {
throw new UnsupportedOperationException();
}
@Override
public Deque<Coordinate> verticalSeam() {
throw new UnsupportedOperationException();
}
}
```
Pour tester, vous devez modifier dans la classe `Controller` du package `fr.insa_rennes.sdd.javafx.controller` la méthode `loadImage` pour utiliser le `SeamCarverDP` à la place du `SeamCarverDijkstra`.
```java
@FXML
private void loadImage() {
FileChooser fileChooser = new FileChooser();
fileChooser.setTitle("Open Image File");
File file = fileChooser.showOpenDialog(pane.getScene().getWindow());
seamCarver = Optional.ofNullable(file)
(7) .map(f -> new SeamCarverDijkstra(new Picture(new Image(f.toURI().toString(), MAX_SIZE, MAX_SIZE, true, true))));
if (seamCarver.isPresent()) {
Image image = seamCarver.get().picture().image();
zoomRatio = Math.min(canvas.getWidth() / image.getWidth(), canvas.getHeight() / image.getHeight());
}
draw();
}
```
À la ligne 7 il faut remplacer l'utilisation de `SeamCarverDijkstra` par `SeamCarverDP`.
Vous pouvez ensuite lancer l'application et vous devriez remarquer une meilleure réactivité maintenant (essayer de réduire la taille de la fenêtre par exemple).
</article>