# Installation Elasticsearch & Kibana avec Docker
Vous pouvez aussi les installer sans Docker, mais par le paquet d'installation depuis le [site officiel](https://www.elastic.co/guide/en/elasticsearch/reference/current/install-elasticsearch.html#elasticsearch-install-packages)
## Installer et lancer Elasticsearch
``` bash
# Creer un network
docker network create elastic
# Télécharger l'image Elastic
docker pull docker.elastic.co/elasticsearch/elasticsearch:8.6.0
# Lancer l'image
docker run --name es-node01 --net elastic -p 9200:9200 -p 9300:9300 -t docker.elastic.co/elasticsearch/elasticsearch:8.6.0
```
Si vous obtenez "bootstrap check failure [1] of [1]: max virtual memory areas vm.max_map_count [65530] is too low", vous pouvez vous référer à [la solution ci-dessous](#troubleshooting)
**Note** : Durant le lancement dans le terminal ou dans Docker desktop vont apparaitre des informations suivantes (pensez à les copier-coller dans un fichier, elles vont vous servir après, surtout le mot de passe pour votre user "elastic" et l'enrollment token pour Kibana) :
```
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
-> Elasticsearch security features have been automatically configured!
-> Authentication is enabled and cluster connections are encrypted.
-> Password for the elastic user (reset with `bin/elasticsearch-reset-password -u elastic`):
IvI2WWQ89b2jXfeFvDHN
-> HTTP CA certificate SHA-256 fingerprint:
ae12d482d7f1e668c091d17d81e94b13f1d6ab45bb6afafd0c9de6a66fadbe57
-> Configure Kibana to use this cluster:
* Run Kibana and click the configuration link in the terminal when Kibana starts.
* Copy the following enrollment token and paste it into Kibana in your browser (valid for the next 30 minutes):
eyJ2ZXIiOiI4LjQuMyIsImFkciI6WyIxNzIuMTkuMC4yOjkyMDAiXSwiZmdyIjoiYWUxMmQ0ODJkN2YxZTY2OGMwOTFkMTdkODFlOTRiMTNmMWQ2YWI0NWJiNmFmYWZkMGM5ZGU2YTY2ZmFkYmU1NyIsImtleSI6IlQwbG81SU1CNm9sMWo5bnN0YklrOjJsdXBWM0hPUU1pWmN4cl9JNGZ1elEifQ==
-> Configure other nodes to join this cluster:
* Copy the following enrollment token and start new Elasticsearch nodes with `bin/elasticsearch --enrollment-token <token>` (valid for the next 30 minutes):
eyJ2ZXIiOiI4LjQuMyIsImFkciI6WyIxNzIuMTkuMC4yOjkyMDAiXSwiZmdyIjoiYWUxMmQ0ODJkN2YxZTY2OGMwOTFkMTdkODFlOTRiMTNmMWQ2YWI0NWJiNmFmYWZkMGM5ZGU2YTY2ZmFkYmU1NyIsImtleSI6IlVVbG81SU1CNm9sMWo5bnN0YkkzOktFbkRKYlVOVDhTMXQyMklSZDlEMncifQ==
If you're running in Docker, copy the enrollment token and run:
`docker run -e "ENROLLMENT_TOKEN=<token>" docker.elastic.co/elasticsearch/elasticsearch:8.4.3`
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
```
taper les commandes suivantes, vous pouvez les taper en ouvrant un nouveau terminal ou sur le terminal courant en appuyant ctr+c (cela ne va pas éteindre container de ES)
``` bash
# Copier le certificat
docker cp es-node01:/usr/share/elasticsearch/config/certs/http_ca.crt .
# Lancer la commande
curl --cacert http_ca.crt -u elastic https://localhost:9200
```
référez-vous au [problème 2 ci-dessous](#troubleshooting) si "curl: (77) error setting certificate file: http_ca.crt" apparaît.
Réponse attendu :

vous pouvez aussi tester par le navigateur, via le lien: https://localhost:9200/
, (username: elastic, password: le mot de passe vient d'être généré)
``` bash
### Installer Kibana
docker pull docker.elastic.co/kibana/kibana:8.6.0
docker run --name kib-01 --net elastic -p 5601:5601 docker.elastic.co/kibana/kibana:8.6.0
```
Pour accéder au Kibana, vous devez cliquer le lien affiché dans le terminal et taper le premier enrollment token généré, si votre enrollment token est expiré, référez-vous au [problème 3 ci-dessous](#troubleshooting)
Connectez-vous avec le même compte (username: elastic, password: le mot de passe vient d'être généré)
## TroubleShooting
Si vous êtes sur Ubuntu et vous rencontrez des problèmes, ne vous inquiétez pas, voici une liste de problèmes courants et leurs solutions
``` bash
# 1. Quand je lance mon image, j'ai l'erreur "max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
# ERROR: Elasticsearch did not exit normally - check the logs at /usr/share/elasticsearch/logs/docker-cluster.log"
#La solution permanente : exécutez les commandes suivantes
sudo sh -c 'echo "vm.max_map_count = 262144" >> /etc/sysctl.conf'
sudo sysctl -p
#La solution temporaire (disparaît après le redémarrage) :
sysctl -w vm.max_map_count=262144
# 2. Quand j'exécute la commande "url --cacert http_ca.crt -u elastic https://localhost:9200", j'ai l'erreur "curl: (77) error setting certificate"
# Trouvez le fichier "http_ca.crt" dans le répertoire courant et exécutez les commandes suivantes
sudo chmod 711 http_ca.crt
sudo curl --cacert http_ca.crt -u elastic https://localhost:9200
# 3. Mon enrollement token a expiré et j'arrive pas à me connecter à Kibana
# Regénérer un enrollement
docker exec -it es-node01 /usr/share/elasticsearch/bin/elasticsearch-create-enrollment-token -s kibana
```
## Partie 1 : CRUD opérations d'Elastic Search avec Kibana
Aller dans Kibana, dans la section "Management" de la page d'acceuil, cliquer Dev Tools>Console, nous allons répondre aux questions suivantes dans le terminal Kibana en utilisant les requêtes qu'on a vu en cours.
#### Q1. Ajouter une personne qui s'appelle Brayan qui a 23 ans et qui a un solde 10000 dans l'index "customer", on donne 1 comme son ID
Donnée Json:
>{
"name" : "Brayan",
"age" : 23,
"balance" : 10000}
Résultat attendu :
> {
"_index": "customer",
"_id": "1",
"_version": 4,
"result": "created",
"_shards": {
$~~~~~~~~~~$ "total": 2,
$~~~~~~~~~~$ "successful": 1,
$~~~~~~~~~~$"failed": 0
},
"_seq_no": 4,
"_primary_term": 1
}
#### Q2. Ajouter 10000 dans le solde de Brayan
Résultat attendu :
>{
"_index": "customer",
"_id": "1",
"_version": 10,
"result": "updated",
"_shards": {
$~~~~~~~~~~$ "total": 2,
$~~~~~~~~~~$ "successful": 1,
$~~~~~~~~~~$ "failed": 0
$~~~~~$},
"_seq_no": 10,
"_primary_term": 1
}
#### Q3. Get l'information de Brayan (Indice : son ID est 1)
Résultat attendu :
> {
"_index": "customer",
"_id": "1",
"_version": 11,
"_seq_no": 11,
"_primary_term": 1,
"found": true,
"_source": {
$~~~~~~~~~~$"name": "Brayan",
$~~~~~~~~~~$"age": 23,
$~~~~~~~~~~$"balance": 20000
$~~~~~$}
}
#### Q4. Ajouter des personnes dans l'index customer
**Note** Pour ajouter plusieurs documents en même temps, nous allons utiliser la requête POST nomDeIndex/_bulk
Donnée Json:
> { "create":{ } }
{ "name" : "toto","age" : 2,"balance" : 1000}
{ "create":{ } }
{ "name" : "titi","age" : 60,"balance" : 5000}
{ "create":{ } }
{ "name" : "tata","age" : 30,"balance" : 200}
{ "create":{ } }
{ "name" : "tutu","age" : 15,"balance" : 0}
Résultat attendu :
> {
"took": 6,
"errors": false,
"items": [
{
"create": {
$~~~~~~~~~~$"_index": "customer",
$~~~~~~~~~~$"_id": "vVNv6IUBKQImO5wM_QrR",
$~~~~~~~~~~$"_version": 1,
$~~~~~~~~~~$"result": "created",
$~~~~~~~~~~$"_shards": {
$~~~~~~~~~~~~~~~~~~~~$"total": 2,
$~~~~~~~~~~~~~~~~~~~~$"successful": 1,
$~~~~~~~~~~~~~~~~~~~~$"failed": 0
$~~~~~~~~~~$},
$~~~~~~~~~~$"_seq_no": 12,
$~~~~~~~~~~$"_primary_term": 1,
$~~~~~~~~~~$"status": 201
$~~~~~~$ }
$~~~$ }, etc...]}
On peut constacter que les IDs des documents sont distribués automatiquement par ES avec la requête POST
#### Q5. Trouver le client qui s'appele toto en utilisant la "query match"
Résultat attendu
>{
"took": 2,
"timed_out": false,
"_shards": {
$~~~~~~~~~~$"total": 1,
$~~~~~~~~~~$"successful": 1,
$~~~~~~~~~~$"skipped": 0,
$~~~~~~~~~~$"failed": 0
},
"hits": {
$~~~~~~~~~~$"total": {
$~~~~~~~~~~~~~~~$"value": 1,
$~~~~~~~~~~~~~~~$"relation": "eq"
},
"max_score": 1.3862942,
"hits": [{
$~~~~~~~~~~$"_index": "customer",
$~~~~~~~~~~$"_id": "vVNv6IUBKQImO5wM_QrR",
$~~~~~~~~~~$"_score": 1.3862942,
$~~~~~~~~~~$"_source": {
$~~~~~~~~~~~~~~~$"name": "toto",
$~~~~~~~~~~~~~~~$"age": 2,
$~~~~~~~~~~~~~~~$"balance": 1000
$~~~~~~~~~~~~~$}
$~~~~~~~~~$}]
$~~~~~~$}
}
#### Q6. Trouver les clients qui sont majeurs. (Indice : on peut utiliser la query range, avec opération "gte" qui signifie >= )
Résultat attendu
> On a 3 hits en total, et dans le champs "hits" on peut retrouver Brayan, titi et tata.
#### Q7. Trouver le solde le plus élevé. (Indice : on peut utiliser l'aggregation max)
Résultat attendu
> On peut retrouver dans le résultat :
"aggregations": {
$~~~~~~~~~$"maxBalance": {
$~~~~~~~~~~~~~~$"value": 20000
$~~~~~~~~~~~~~$}
}
#### Q8. Calculer le solde moyen de cet index
> On peut retrouver dans le résultat :
"aggregations": {
$~~~~~~~~~$"avg_balance": {
$~~~~~~~~~~~~~~$"value": 5240
$~~~~~~~~~~~~~$}
}
#### Q9. Calculer la proportion de personnes dont le solde est strictement inférieur à 1000
(pas sur pour cette question)
Vous allez importer le fichier **account.json** dans kibana. Vous suivez les étape suivantes.
Vous cherchez **Integrations** dans le cosole et puis **Upload a file**.
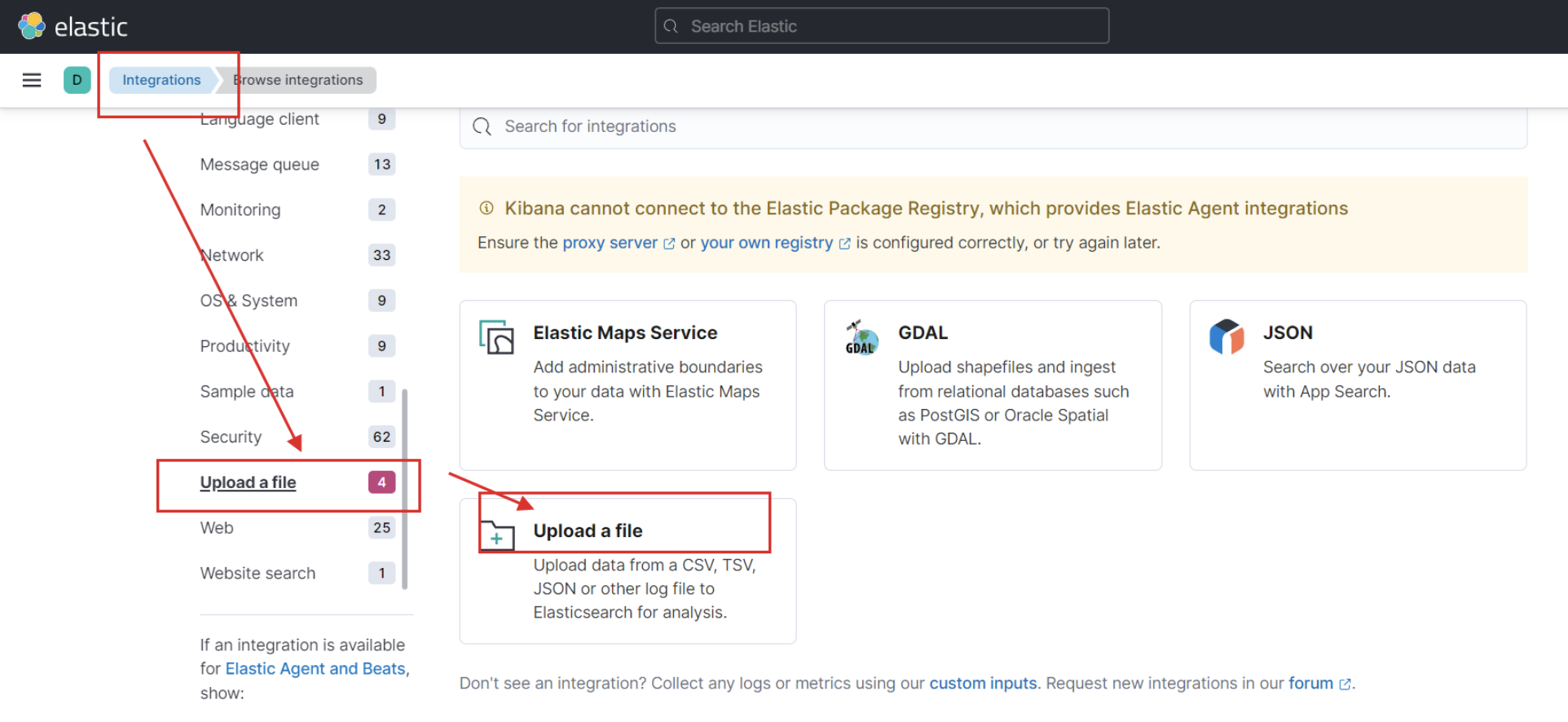
Vous ajoutez le fichier **account.json**.
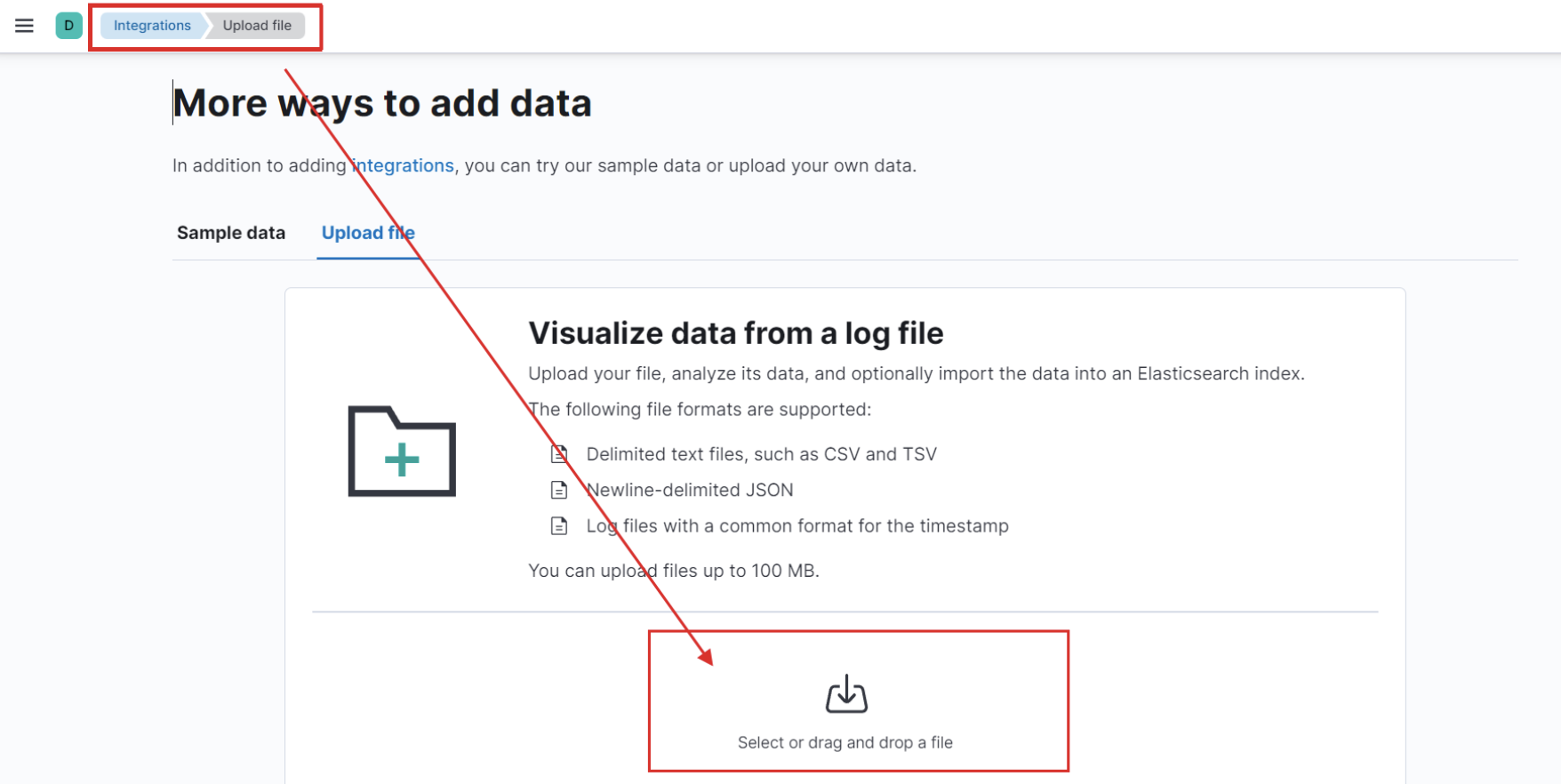
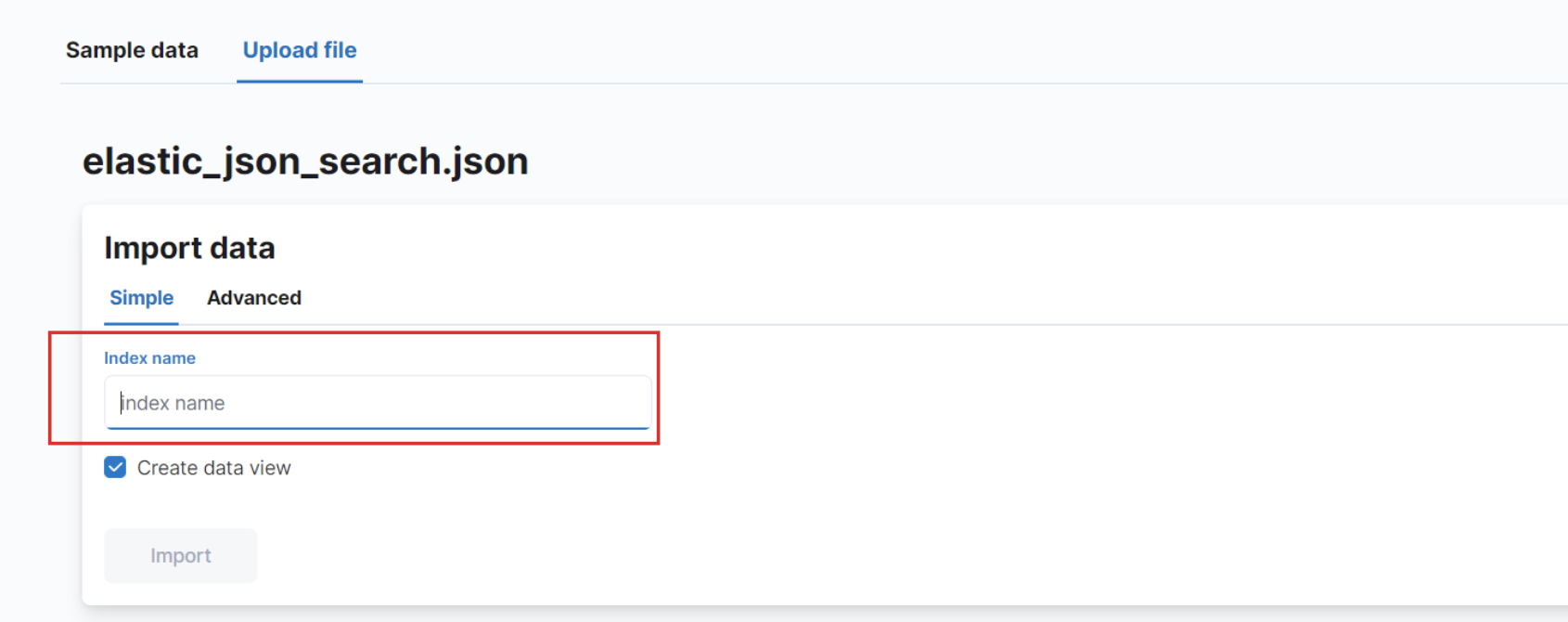
Une fois vous avez finit l'importer, vous cliquez sur le boutton **import** en bas à gauche. Vous donnez un nom au champs **index name**. Attention, vous utilizerez ce nom pour le tp suivant.
#### Q1. Grouper par l'âge de 20 à 30 ans, l'âge de 30 à 40 ans et l'âge plus de 40 ans et calculer l'âge moyenne
**Note** On utilise **ranges** aggregation pour grouper par l'âge
#### Q2. Grouper par l'âge de 20 à 30 ans, l'âge de 30 à 40 ans et l'âge plus de 40 ans et calculer le salaire moyenne pour chaque groupe
#### Q3. Grouper la ville et le sexe et calculer le salaire moyenne pour chaque groupe.
#### Q4. Filter les villes Rennes et Paris, grouper par la ville et le sexe, calculer le salaire moyenne pour chaque groupe.
## Partie 2 : Elasticsearch Client sur Python
Pour cette partie là, on exploitera comment intéragir avec Elasticsearch sur Python. Vous pouvez utiliser IDE comme vous voulez.
**Note** : à part d'Elasticsearch, d'ici, on a également besoin de librairie pandas
#### Q1. Installer Elasticsearch, importer dans Python
>pip3 install elasticsearch
Dans votre script python :
``` bash
import elasticsearch
from elasticsearch import Elasticsearch
#Voir la version elasticsearch :
print (elasticsearch.VERSION)
```
D'ici, j'utilise la version 8.6.0
#### Q2. Connecter avec le server Elasticsearch
``` bash
ELASTIC_PASSWORD = {Votre password}
client = Elasticsearch(
"https://localhost:9200",
ca_certs="path/vers/http_ca.cert",
basic_auth=("elastic", ELASTIC_PASSWORD))
#Il faut checker si tout va bien en lancant :
client.info()
```
La réponse doit rassemble à cela :

Vous pouvez également prendre les données qu'on a créé dans la 1ère partie :
``` bash
client.search(index='customer',body={"query": {"match_all": {}}})
```
#### Q3. Traitement les données
Pour la suite de TP, nous vous donnons un dataset qui est les tweets qui ont hashtag #Farmersprotest. Dans cette question, nous avons besoin de nettoyer les données avant injecter dans Elasticsearch
#### 3.1. Lire les données au format JSON
Hint: Utiliser pandas.read_json('/path/vers/des/données',lines=True)
#### 3.2. Filtrer
Nous n'utilisons que les tweets en Anglais et nous ne voulons pas de doublons. En plus, il n'y a que les colonnes : id, date, user, renderedContent qui nous servirons pour la suite. Renommer le champ id -> tweetID pour distinguer. La table résultant appelé raw_tweets
Appeler la fonction head() pour voir les résultats
#### 3.3. Flatten nested champ
Nous voyons que le champ "user" est nested, essayons de créér un table à partir de ce champ. Supprimer de doublons. Nous ne gardons que les colonnes : id, location. Renommer le champ id -> userID pour distinguer. La table résultant appelé users
Hint: Utiliser pandas.json_normalize, il faut importer avant utiliser
#### 3.4. Créer la table finale
La table finale appelé "tweets" est créé en mergent les 2 tables précédentes.
#### Q4. Injection les données dans Elasticsearch
## Partie 3 : Agrégation de données et visualisation dans Kibana